
Learning Objectives
Following this assignment students should be able to:
- connect to a remote database and execute simple queries
- integrate database and R workflow
- export output data from R to database
- tidy data table with redundant fields or overfilled cells
Reading
-
Topics
dplyrtidyr
-
Readings
dplyrdatabasestidyrvignette- Optional Resources:
Lecture Notes
Exercises
-- Source and Query --
This is a follow up to the Basic Queries filtering problem.
It is clear Dr. Undómiel appreciates your skill working with large databases and she seems to expect you will maintain your benevolence. (Such is a fair expectation of a true wizard). This time though, she’s looking for some extra detail in her queries. She’s curious if desert rodents are dimorphic in size.
- Download a new copy of the Portal database.
- Connect to
portal_mammals.sqliteas objectportaldbusingdplyr. - Start by reminding yourself about which tables are in the database using
src_tbls() - Then remind yourself of the fields in the
surveysandplotstables using the list subset operator$ops$vars. - Select and print out the average hind foot length and average weight of:
- all Dipodomys spectabilis individuals on the control plots
- male D. spectabilis on the control plots
- female D. spectabilis on the control plots
-- Manipulate Query --
This is a follow-up to Source and Query.
Dr. Undómiel agrees with you that the difference in male and female D. spectabilis hind foot length and weight seems pretty small, but wants to make a more detailed comparison. She wants you to find the male and female hind foot length and weight for all species of rodent on all of the plots (not just the controls) and quantitatively define the size differences among species.
-
Produce a data frame with
species_id,sex,avg_hindfoot_length, andavg_weightfor each species. Your data frame should have two rows for each species, one row for each sex.You can solve this problem with
dplyrin a variety of ways including writing a query or using data manipulation verbs to group and select the data. You could also decide to useforloops orapplystatements. Take whichever approach you like best. -
Write a function that determines if the absolute difference in average male and female size is less than the standard deviation of sizes for all individuals (
abs(male - female) <= stdev). -
Manipulate the data so that you have a local data frame that has average male and female
hindfoot_lengthandweightand the standard deviations in a single row for each species. -
Use
transmute()and anifelse()with your function to take each specieshindfoot_lengthandweightfrom your local data frame and make a new data frame as that labels the results of your simple calculation as"SAME"or"DIFF".You may find that you get an
Error: non-numeric argument to binary operator. The missing size data causesmean()to return results as acharacter. Remove the missing data from your query or re-class the resultsas.numeric()to make your calculation.
-
-- Copy to Database --
Dr. Undómiel has decided to focus on the change in size of a few target rodent species over the course of the experiment(1977-2002). She has chosen Dipodymys spectabilis, Onychomys torridus, Perymiscus erimicus, Chaetodipus penicillatus.
Write a script that uses
dplyrto:- Connect to the
portal_mammals.sqlite. - Generate a data frame with
year,species_id, and the average weight per year (avg_weight) for each target species. You may find the%in% c()construction useful for yourfilter(). - Use
copy_to()to include your new data frame inportal_mammals.sqlite. Call it something informative so that Dr. Undómiel can find it easily. Make sure it remains after the connection is terminated usingtemporary = FALSE.
- Connect to the
-- NEON Mammals --
The National Ecological Observatory Network has entered into the construction phase of development and they are already making their data available! NEON collects ecological and environmental data for representative regions of the United States at local to continental scales, including, of course!, small mammal box trapping. We’ve retrieved NEON’s existing small mammal data from Ordway-Swisher Biological Station [NEON Data Use Policy].
- Create a SQLite database called
ordway_mammals.sqlite. - Download the three data tables (capture, plots, traps) and import them into the SQLite database. Familiarize yourself with the tables’ structure.
- Write a query to determine the total number of traps that have been disturbed at each plot. Plot a histogram of the results.
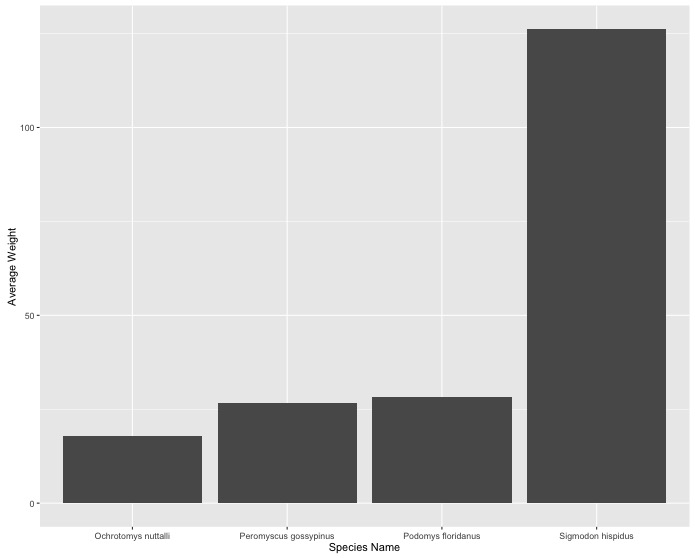
- Determine the average hind foot length and weight of each species collected
for each National Landcover Database class (
nlcdClass). - Plot the average weight of all species with weight measurements from the woody wetlands.
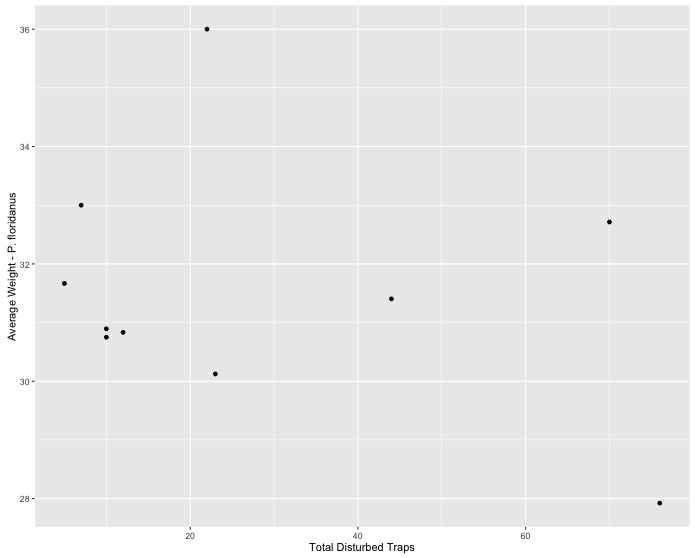
- Create a scatter plot of the relationship between the total number of
disturbed traps and the average weight of Podimus floridanus for each sampling event (
eventID).
- Create a SQLite database called
-- Tree Biomass --
Estimating the total amount of biomass (the total mass of all individuals) in forests is important for understanding the global carbon budget and how the earth will respond to increases in carbon dioxide emissions. Measuring the mass of whole trees is a major effort and requires destructive harvest of the tree. Fortunately, we can estimate the mass of a tree based on its diameter.
There are lots of equations for estimating the mass of a tree from its diameter, but one good option is the equation:
Mass = 0.124 * Diameter2.53
where
Massis measured in kg of dry above-ground biomass andDiameteris in cm DBH (Brown 1997).We’re going to estimate the total tree biomass for trees in a 96 hectare area of the Western Ghats in India. The raw data is available on Ecological Archives. Unfortunately, the data is stored in a poor database structure and using all of the tree stems would be difficult without first tidying up the data. You can have a look at the metadata to get familiar with the data structure.
- Use
tidyrtogather()the raw data into rows for each measured stem. - Write a function that takes a vector of tree diameters as an argument and
returns a vector of tree masses. - Stems are measured in girth (or circumference) rather than diameter. Write a function that takes a vector of circumferences as an argument and returns a vector of diameters (circumference = pi * diameter).
- Use the two functions you’ve written to estimate the total biomass (i.e., the sum of the masses) of trees in this dataset and print the result to the screen.
separate()theSpCodeintoGenusCodeandSpEpCodeand estimate the total biomass per genus in a table. Technically the four letter code doesn’t uniquely identify all of the genera in the dataset, but we’ll assume it does for the purpose of this exercise.
- Use
{kind=link}
{kind=link}
{kind=link}